Try Compass for free
Improve your developer experience, catalog all services, and increase software health.
Articles
Tutorials
Interactive Guides
DevOps Pipeline
A DevOps pipeline is a set of automated processes and tools that allows developers and operations professionals to collaborate on building and deploying code to a production environment.

Tom Hall
DevOps Advocate & Practitioner
DevOps is a revolutionary movement, in that it revolutionizes the siloed organizational structure that separated development and operations. The result is a cultural shift where developers and operations professionals work together, embrace automation, increase deployment speed, and are more flexible.
The resulting DevOps structure has clear benefits: Teams who adopt DevOps practices can improve and streamline their deployment pipeline, which reduces incident frequency and impact. The DevOps practice of “you build it, you run it” is fast becoming the norm and with good reason — nearly every respondent (99%) of the 2020 DevOps Trends Survey said DevOps has had a positive impact on their organization, with nearly half seeing a faster time to market and improved deployment frequency.
Yet implementing DevOps is easier said than done. It takes the right people, processes, and tools to successfully implement DevOps.
What is the DevOps pipeline?
A DevOps pipeline is a set of automated processes and tools that allows both developers and operations professionals to work cohesively to build and deploy code to a production environment. While a DevOps pipeline can differ by organization, it typically includes build automation/continuous integration, automation testing, validation, and reporting. It may also include one or more manual gates that require human intervention before code is allowed to proceed.
Continuous is a differentiated characteristic of a DevOps pipeline. This includes continuous integration, continuous delivery/deployment (CI/CD), continuous feedback, and continuous operations. Instead of one-off tests or scheduled deployments, each function occurs on an ongoing basis.
related material
Get started for free
related material
Learn more about DevOps tools
Considerations for building a DevOps pipeline
Since there isn’t one standard DevOps pipeline, an organization’s design and implementation of a DevOps pipeline depends on its technology stack, a DevOps engineer’s level of experience, budget, and more. A DevOps engineer should have a wide-ranging knowledge of both development and operations, including coding, infrastructure management, system administration, and DevOps toolchains.
Plus, each organization has a different technology stack that can impact the process. For example, if your codebase is node.js, factors include whether you use a local proxy npm registry, whether you download the source code and run `npm install` at every stage in the pipeline, or do it once and generate an artifact that moves through the pipeline. Or, if an application is container-based, you need to decide to use a local or remote container registry, build the container once and move it through the pipeline, or rebuild it at every stage.
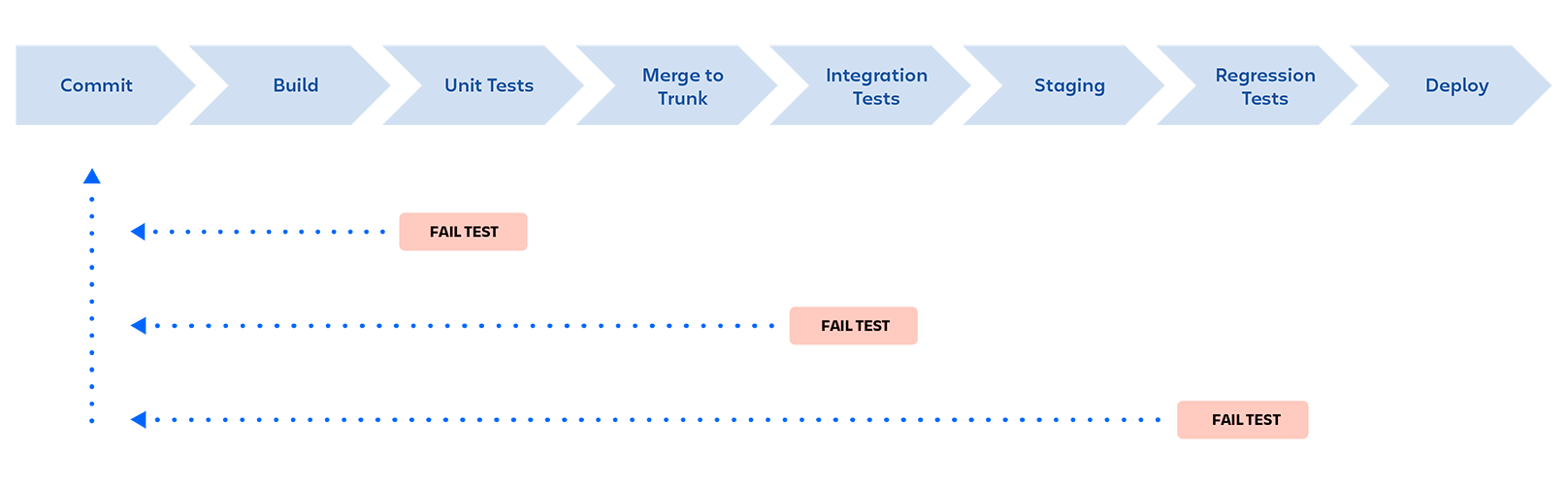
While every pipeline is unique, most organizations use similar fundamental components. Each step is evaluated for success before moving on to the next stage of the pipeline. In the event of a failure, the pipeline is stopped, and feedback is provided to the developer.
Components of a DevOps pipeline
1. Continuous integration/continuous delivery/deployment (CI/CD)
Continuous integration is the practice of making frequent commits to a common source code repository. It’s continuously integrating code changes into existing code base so that any conflicts between different developer’s code changes are quickly identified and relatively easy to remediate. This practice is critically important to increasing deployment efficiency.
We believe that trunk-based development is a requirement of continuous integration. If you are not making frequent commits to a common branch in a shared source code repository, you are not doing continuous integration. If your build and test processes are automated but your developers are working on isolated, long-living feature branches that are infrequently integrated into a shared branch, you are also not doing continuous integration.
Continuous delivery ensures that the “main” or “trunk” branch of an application's source code is always in a releasable state. In other words, if management came to your desk at 4:30 PM on a Friday and said, “We need the latest version released right now,” that version could be deployed with the push of a button and without fear of failure.
This means having a pre-production environment that is as close to identical to the production environment as possible and ensuring that automated tests are executed, so that every variable that might cause a failure is identified before code is merged into the main or trunk branch.
Continuous deployment entails having a level of continuous testing and operations that is so robust, new versions of software are validated and deployed into a production environment without requiring any human intervention.
This is rare and in most cases unnecessary. It is typically only the unicorn businesses who have hundreds or thousands of developers and have many releases each day that require, or even want to have, this level of automation.
To simplify the difference between continuous delivery and continuous deployment, think of delivery as the FedEx person handing you a box, and deployment as you opening that box and using what’s inside. If a change to the product is required between the time you receive the box and when you open it, the manufacturer is in trouble!
2. Continuous feedback
The single biggest pain point of the old waterfall method of software development — and consequently why agile methodologies were designed — was the lack of timely feedback. When new features took months or years to go from idea to implementation, it was almost guaranteed that the end result would be something other than what the customer expected or wanted. Agile succeeded in ensuring that developers received faster feedback from stakeholders. Now with DevOps, developers receive continuous feedback not not only from stakeholders, but from systematic testing and monitoring of their code in the pipeline.
Continuous testing is a critical component of every DevOps pipeline and one of the primary enablers of continuous feedback. In a DevOps process, changes move continuously from development to testing to deployment, which leads not only to faster releases, but a higher quality product. This means having automated tests throughout your pipeline, including unit tests that run on every build change, smoke tests, functional tests, and end-to-end tests.
Continuous monitoring is another important component of continuous feedback. A DevOps approach entails using continuous monitoring in the staging, testing, and even development environments. It is sometimes useful to monitor pre-production environments for anomalous behavior, but in general this is an approach used to continuously assess the health and performance of applications in production.
Numerous tools and services exist to provide this functionality, and this may involve anything from monitoring your on-premise or cloud infrastructure such as server resources, networking, etc. or the performance of your application or its API interfaces.
3. Continuous operations
Continuous operations is a relatively new and less common term, and definitions vary. One way to interpret it is as “continuous uptime”. For example in the case of a blue/green deployment strategy in which you have two separate production environments, one that is “blue” (publicly accessible) and one that is “green” (not publicly accessible). In this situation, new code would be deployed to the green environment, and when it was confirmed to be functional then a switch would be flipped (usually on a load-balancer) and traffic would switch from the “blue” system to the “green” system. The result is no downtime for the end-users.
Another way to think of Continuous operations is as continuous alerting. This is the notion that engineering staff is on-call and notified if any performance anomalies in the application or infrastructure occur. In most cases, continuous alerting goes hand in hand with continuous monitoring.
In conclusion...
DevOps is about streamlining software development, deployment and operations. The DevOps pipeline is how these ideas are implemented in practice and continuous everything is the name of the game, from code integration to application operations.
To learn more about continuous delivery, check out our tutorials for continuous delivery with Bitbucket, which lets you build, test and deploy with integrated CI/CD. These tutorials will help the beginner and the pro achieve continuous delivery with Bitbucket. Ready to jump right in? Get started with Bitbucket Pipelines free.
Share this article
Next Topic
Recommended reading
Bookmark these resources to learn about types of DevOps teams, or for ongoing updates about DevOps at Atlassian.

DevOps community

DevOps learning path